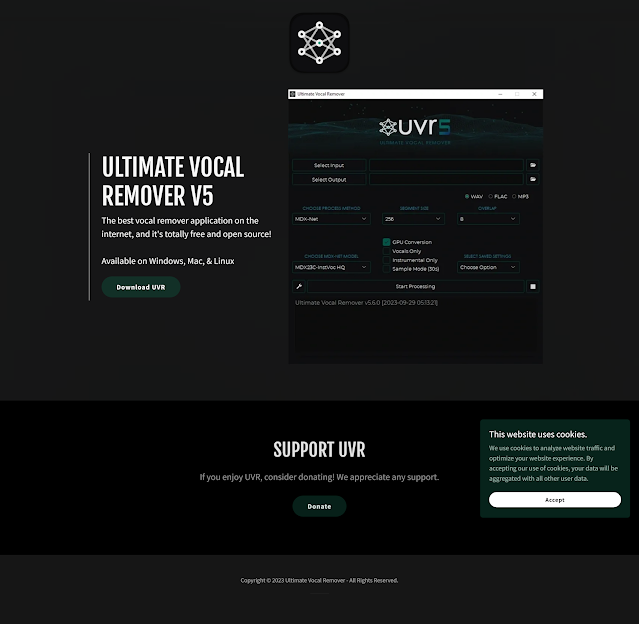
这是我目前测试出来声音克隆效果最好的一种方式 对电脑配置没有高要求 首先自行获取音频文件 Ultimate Vocal Remover用来分离人声和伴奏,消除混响和声 https://ultimatevocalremover.com/ 格式工厂FormatFactory,用来快速转换文件格式 http://formatfactory.org/CN/download.html Audio Slicer https://github.com/flutydeer/audio-slicer 新建4个文件夹,1号,2号,3号,4号 把音频文件放到1号文件夹 打开Ultimate Vocal Remover 点击Select Input 选择你在1号文件夹内放的音频文件 点击Select Output 选择2号文件夹(分离人声和伴奏) 选择正确的文件格式:WAV,FLAC,MP3 CHOOSE PROCESS METHOD,选择Demucs CHOOSE STEM(S),选择Vocals(人声) 勾选GPU Conversion 点击Start Processing 耐心等待一段时间 点击Select Input,选择2号文件夹中_(Vocals)结尾的文件 点击Select Output 选择3号文件夹(消除混响和声) CHOOSE PROCESS METHOD,选择VR Architecture WINDOW SIZE,选择320(最小的那个) AGGRESSION SETTING,选择5 CHOOSE VR MODEL,选择1_HP-UVR 勾选GPU Conversion 点击Start Processing 耐心等待一段时间 *你也可以下载其他算法模型,请自行了解 打开Audio Slicer音频切分(也就是slicer-gui.exe) 放入3号文件夹中以_(Vocals)_(Vocals)结尾的文件(必须要.wav格式) 右侧Minimum Length(ms),输入30000(也就是30秒) 点击Browse...,选择4号文件夹 点击右下角Start 打开4号文件夹检查一下,每段音频不能大于45秒 用浏览器打开网址https://covers.ai/ai-song-generator 我的手机的读写的速度比电脑慢,建议使用电脑操作 Choose or uplo...